Our major research interests include (1) operating systems and system software, (2) big-data systems, (3) maching learning for systems, (4) systems for machine learning, and (5) emerging computer systems and architectures.
Operating Systems and System Software
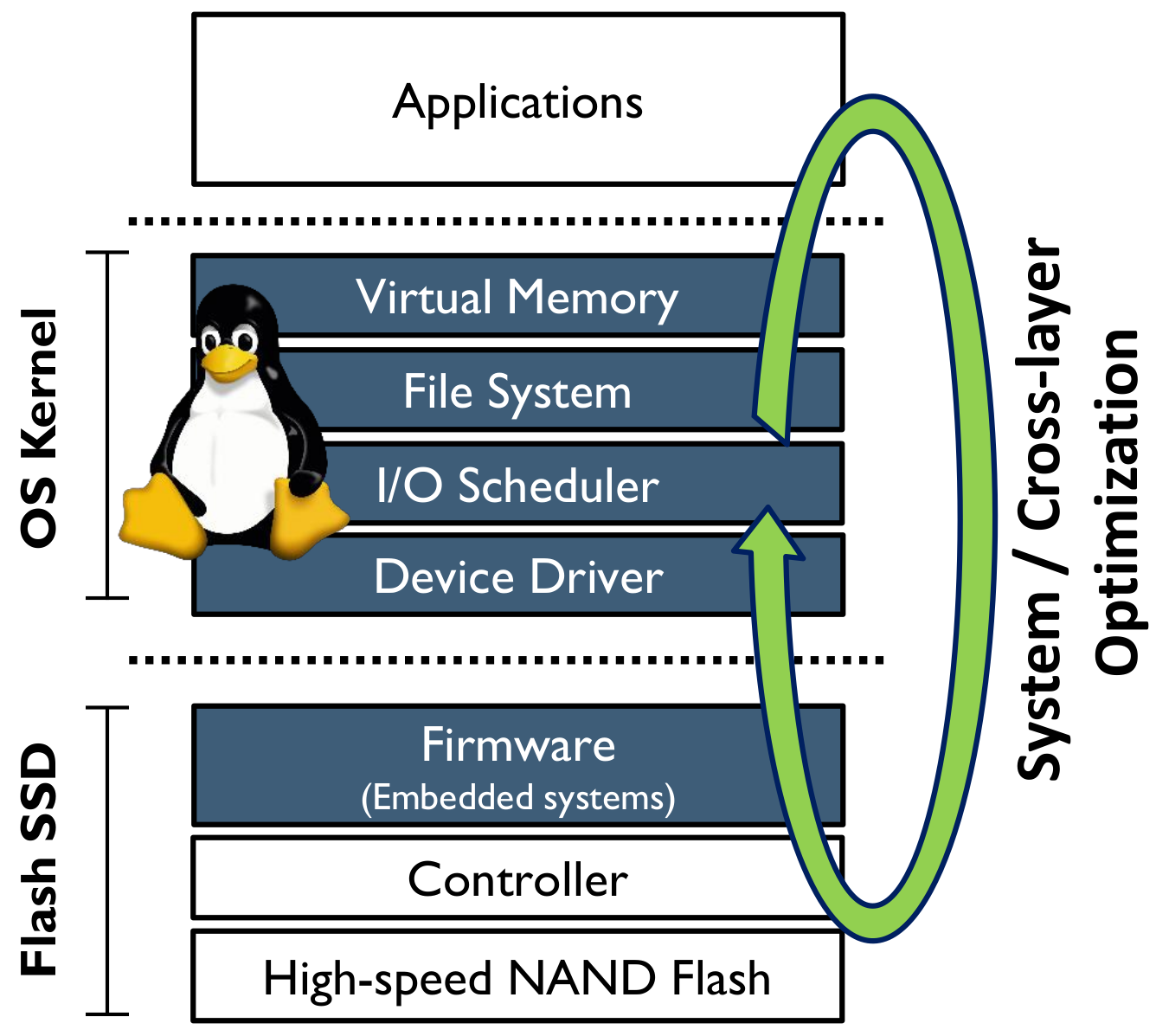
We are system guys; we are working on the design, optimization, and refactoring of system software and operating systems, particularly the Linux kernel, for high-performance memory and storage media. Our main research interests include: 1) optimizing storage engines for data-intensive applications (e.g., key-value store and DBMS), 2) developing memory management engines for next-generation non-volatile memory (e.g., Intel’s Optane), 3) designing file systems for emerging storage devices (e.g., ZNS and Key-value SSDs), and 4) refactoring storage firmware (e.g., a flash translation layer) to realize higher I/O performance with better economics in terms of power, space, and costs.
Beyond research efforts mentioned above, our ultimate goal is to design and implement a new OS architecture which can deal with large amounts of data efficiently, providing full advantage of latest fast memory and storage devices with data-intensive applications. Various kernel design approaches, such as microkernel and exokernel, are considered to be promising candidates to realize this goal.
Big-data Systems
Building high-performance and resource-efficient big-data platforms is one of our primary research interests. From algorithms to systems, we investigate all the important issues across various system layers and develop new systems that address critical bottlenecks in dealing with large amounts of data. For example, we redesign the LSM-tree algorithm, which is widely used for popular NoSQL databases (e.g., Redis, Cassendra, and RocksDB), integrate it into a storage device, and build up file systems on the device. This approach greatly improves file access performance by up to 50x over traditional systems. Together with MIT, we also develop a data analytic machine which boosts up SQL-query performance of column databases by embedding SQL processing units into memory and storage devices.

Machine Learning for Systems
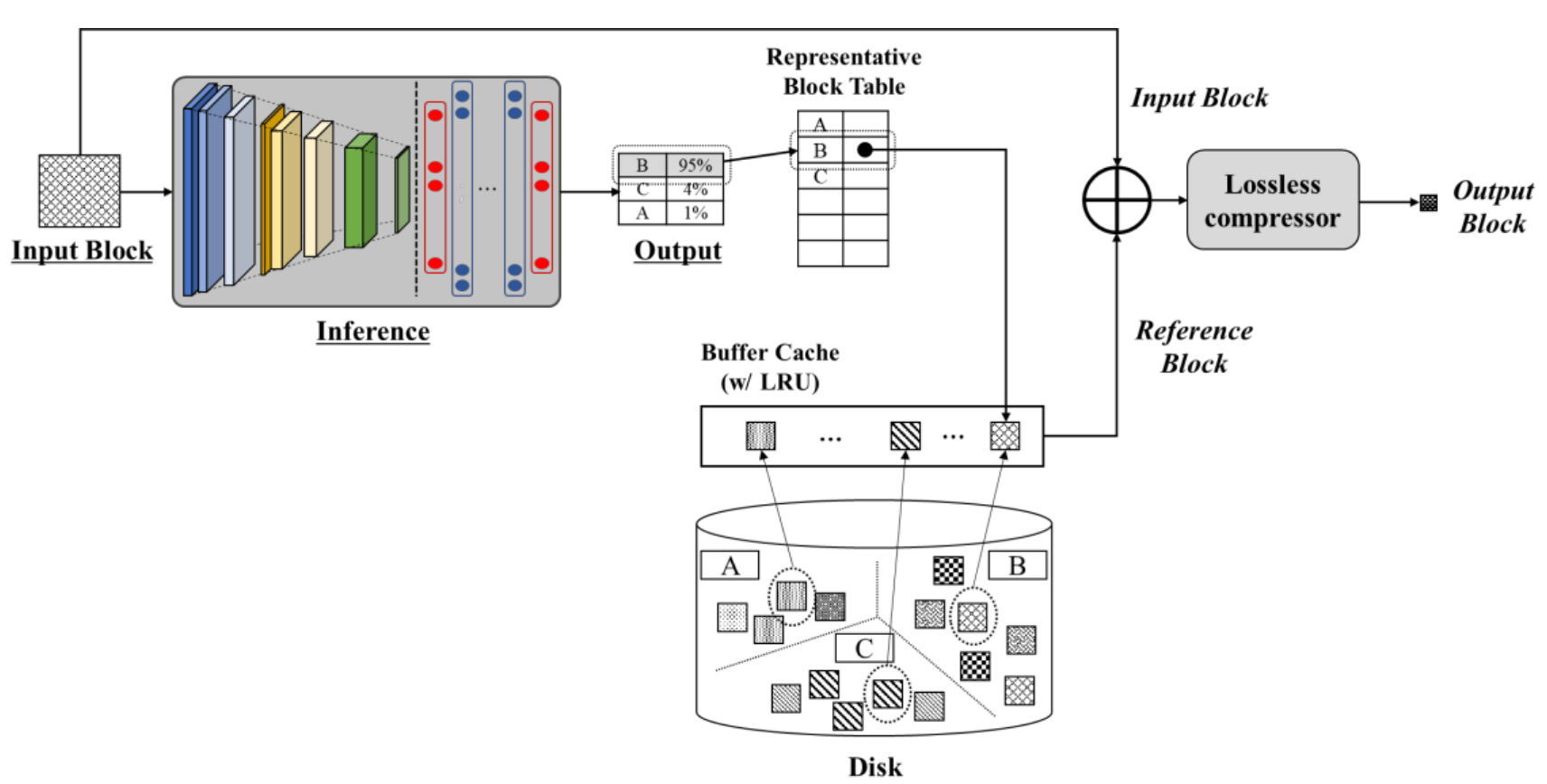
We are actively studying various machine learning (ML) algorithms to solve important system problems. One of our research topics is to use ML algorithms for delta compression. Delta compression is a representative technique that increases the effective capacity of storage systems by preventing similar blocks (or bit patterns) from being stored in data storage. Traditional heuristics and algorithms often fail to find similar blocks. To address such a fundamental limitation, we develop a new ML-based compression technique. Our technique combines and orchestrates various ML algorithms (e.g., K-means clustering, learning-to-hash, and approximate nearest neighbors) to find the most similar block in a candidate data set, thereby providing a much higher compression ratio than traditional approaches. Another topic is to use learned index for building memory-efficient storage systems. To this end, we redesign piecewise linear regression (PLR) so that it indexes large amounts of data while consuming tiny DRAM – only 1% – compared to traditional indexing algorithms. Finally, we also develop ransomware detection techniques using deep-learning algorithms. Our algorithm is able to detect whether given data is encrypted by ransomware, which enables us to backup victim data in safe locations.
Systems for Maching Learning
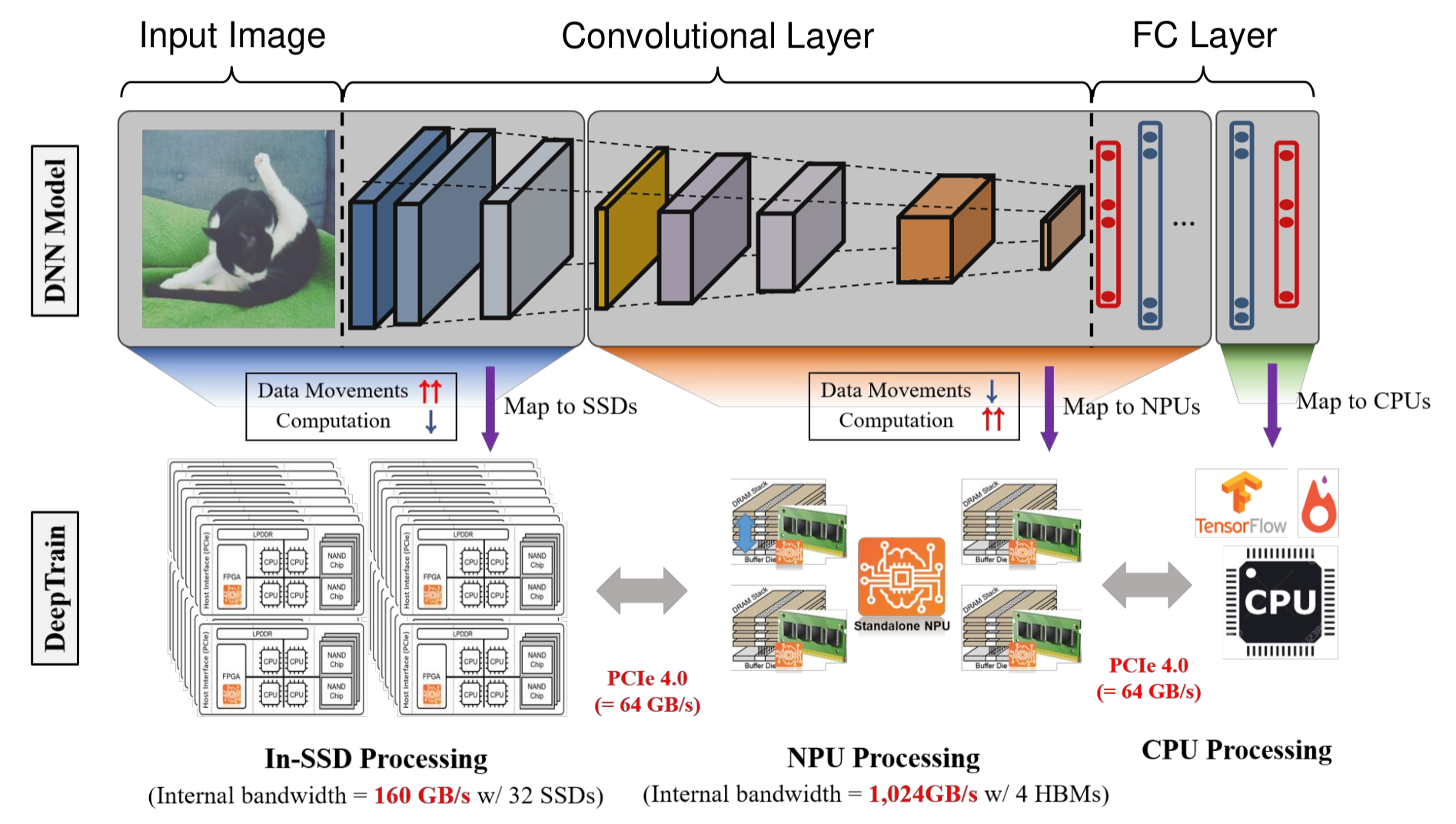
We are devoted to developing new system architectures for accelerating machine learning platforms, including recommender systems (e.g., Facebook’s DLRM), PyTorch, and TensorFlow. Our key approach for this is to offload lightweight ML operations onto the memory- or storage-side. By performing training or inference operations near data, it greatly reduces amounts of data transferred to host CPUs, and thus improves training/inference throughputs and reduces energy consumption. Our case study using Facebook’s DLRM shows that offloading embedding operations can reduce overall response times to users’ queries. As another case study, we are developing a TensorFlow-based ML platform that accelerates training and inference speed by putting part of neural network layers (e.g., feature extraction) onto the storage side. Our preliminary results show that our platform can provide scalable inference and training performance, regardless of amounts of data stored in systems.
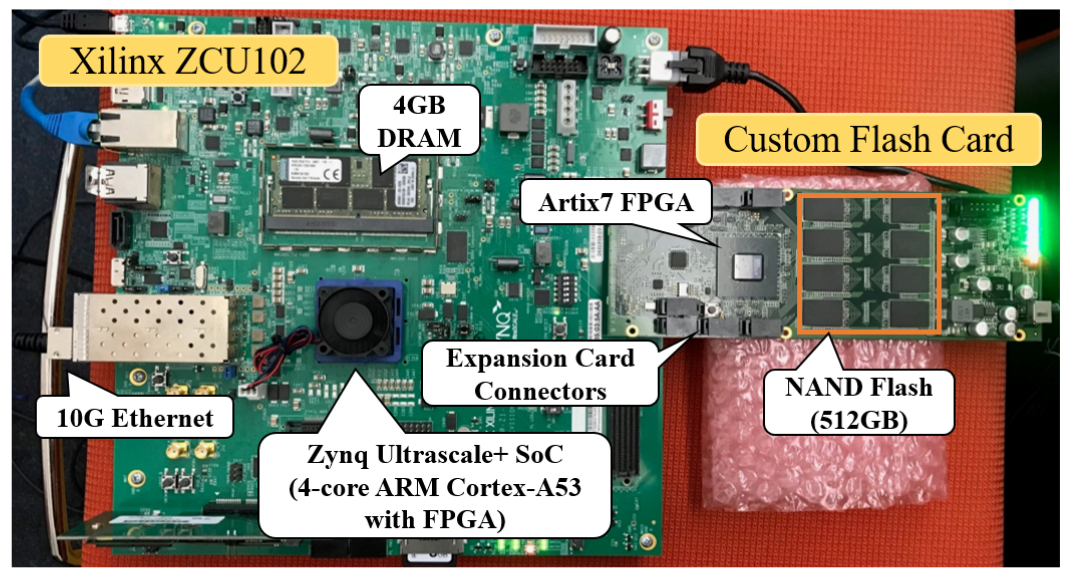
Emerging Computer Systems and Architectures
Many of our research topics are highly associated with emerging computing systems that push more intelligence near data. To pursue this goal, we are developing a high-performance memory and storage platform. Our storage prototype is based on Xilinx Ultra-scale ZCU102 which is equipped with ARM Cortex-A53 CPU, ARM Cortex-R5 CPU, 4GB DRAM, and FPGA fabrics. An in-house flash card is directly attached to the ZCU102 though high-speed FMC ports. This prototype board enables us to develop and evaluate a variety of storage management algorithms and in-store computing accelerators. In addition to ZCU102, our group also has another prototype boards, including DragonFire Cards and Xilinx Alveo, which are also being used for our near-data processing study.